
Optimize your Deep Learning models with Post-Training Optimization from Intel OpenVINO


Who doesn't want to reach the best ever performance from a Deep learning model!!!
Generally, performance means how fast the model processes the live data. Two key metrics are used to measure the performance: latency and throughput are fundamentally interconnected.
Intel has many tools and libraries are responsible to help the community to optimize the Deep Learning models whether during the training phase or post-training phase (after the training is finished).
With the OpenVINO there are two primary ways of improving the inference performance, namely model- and runtime-level optimizations. These two optimizations directions are fully compatible;
- Model optimizations includes model modification, such as quantization, pruning, optimization of preprocessing, etc.
- Runtime (Deployment) optimizations includes tuning of model execution parameters, and for more information for this optimization way, please check this link.
Regarding Model-level Optimization, OpenVINO provides several tools to optimize models at different steps of model development:
Model Optimizer implements optimization to a model, most of them added by default, but you can configure mean/scale values, batch size, RGB vs BGR input channels, and other parameters to speed up preprocess of a model
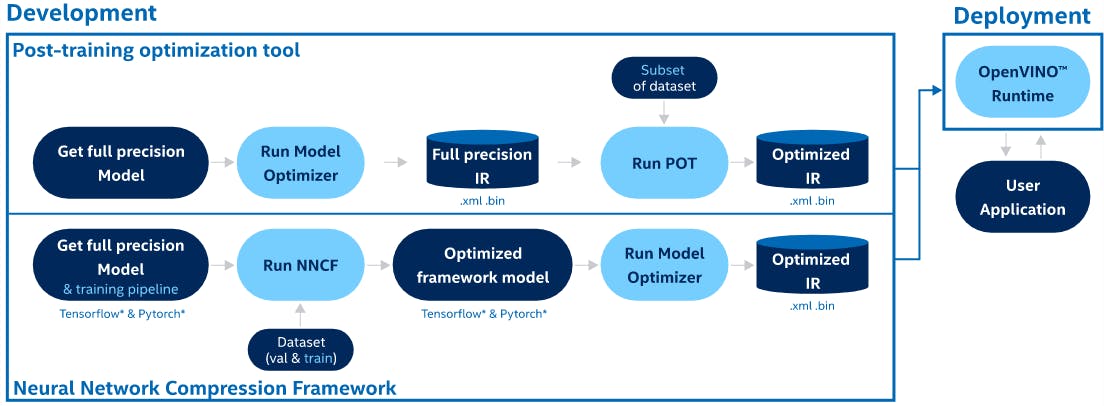
Post-training Optimization tool (POT) is designed to optimize the inference of deep learning models by applying post-training methods that do not require model retraining or fine-tuning, for example, post-training 8-bit quantization.
Neural Network Compression Framework (NNCF) provides a suite of advanced methods for training-time model optimization within the DL framework, such as PyTorch and TensorFlow. It supports methods, like Quantization-aware Training and Filter Pruning. NNCF-optimized models can be inferred with OpenVINO using all the available workflows.
In this blog we will focus more on Optimizing models post-training by POT
Post-training Optimization tool
Almost all the Deep Learning models are trained in the cloud or data centers. And such training often takes place with floating-point 32-bit arithmetic to cover a wider range for the model’s weights. But where do these models get deployed? Mostly on the edge, using hardware with low computational capacity compared to the systems they had been trained on.

The motivations for low precision are as following:
- consuming low power, low memory bandwidth and low storage
- Achieving higher performance
But everything comes with a price and the price here is the accuracy, so that we need to maintain acceptable accuracy loss
Don’t worry. The OpenVINO Toolkit for model quantization also has some calibration tools that can help you quantize models while keeping the model’s prediction capability intact to a large extent. This is where the Post-Training Optimization Tool (POT) plays a major role.
Post-training model optimization is the process of applying special methods without model retraining or fine-tuning, for example, post-training 8-bit quantization. Therefore, this process does not require a training dataset or a training pipeline in the source DL framework.
There're some things definitely important for the POT to work on the trained model;
- You need a trained, full-precision Deep Learning model, either FP32 or FP16. And you’ll have to convert this model first to OpenVINO’s IR (Intermediate Representation) format.
- Also, a sample subset data, preferably the validation data, on which the original, full-precision models have been trained for calibration.
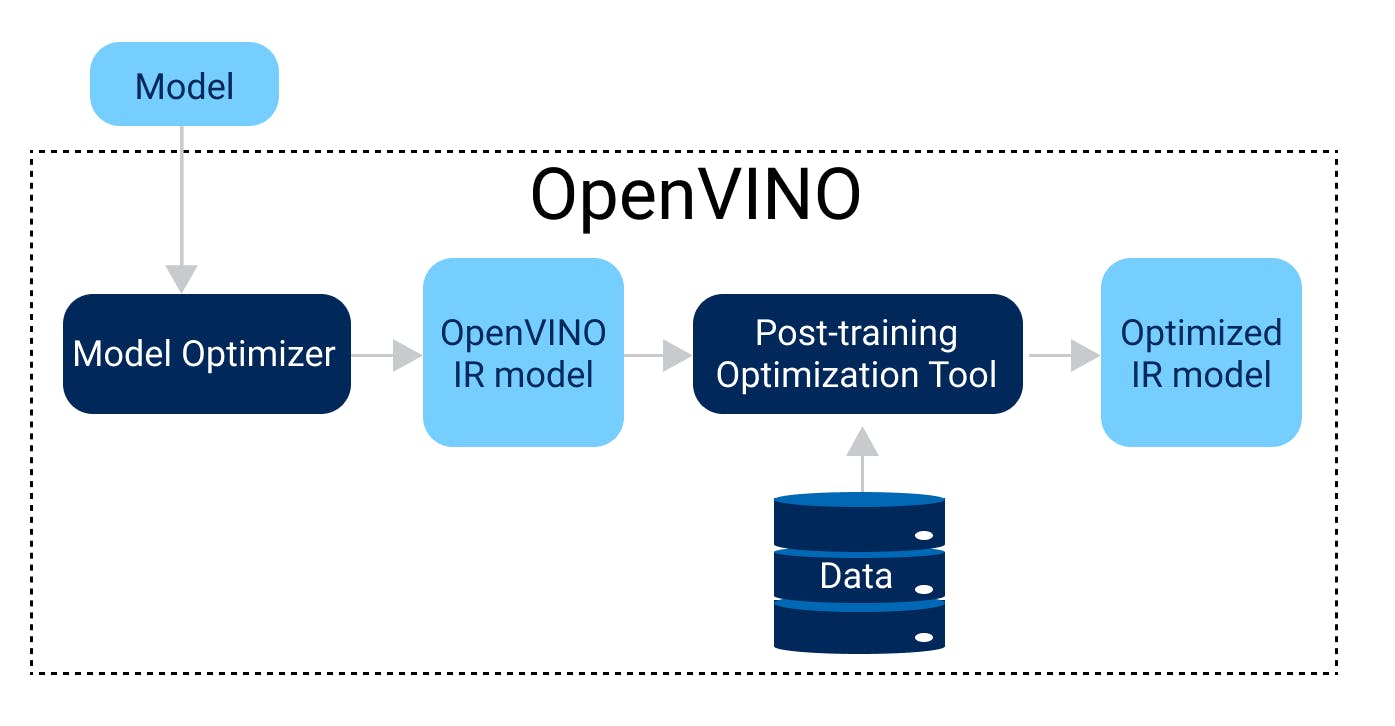
Hardware platforms support different integer precision and quantization parameters, for example 8-bit in CPU, GPU, VPU. POT abstracts this complexity by introducing a concept of “target device” that is used to set quantization settings specific to the device. The target_device parameter is used for this purpose.
The main advantage of using the OpenVINO Post Training Optimization Tool is that it automates the process of model quantization. But there’s more. It also provides two distinct but useful methods:
- DefaultQuantization; is a recommended method that provides fast and accurate results in most cases.
- AccuracyAwareQuantization; is an advanced method that allows keeping accuracy at a predefined range at the cost of performance improvement in case when Default Quantization cannot guarantee it.
We love looking at results, here's performance benchmark of Full-Precision models - the following benchmark was performed on Intel 8th gen.
benchmark_app -m <directory after converting to IR files>/public/yolo-v4-tiny-tf/FP32/yolo-v4-tiny-tf.xml
output
Count: 1720 iterations
Duration: 60189.45 ms
Latency:
Median: 144.42 ms
AVG: 139.71 ms
MIN: 108.85 ms
MAX: 225.29 ms
Throughput: 28.58 FPS
Performance Benchmarking of Quantized Model
benchmark_app -m <directory after quantizing to INT8>/yolov4_int8/optimized/yolo-v4-tiny.xml
output
Count: 3108 iterations
Duration: 60178.33 ms
Latency:
Median: 78.53 ms
AVG: 77.28 ms
MIN: 57.61 ms
MAX: 143.96 ms
Throughput: 51.65 FPS
For more Model Accuracy for INT8 and FP32 Precision, please check this link