

Machine learning (ML) models have been deployed successfully across a variety of use cases and industries, but due to the high computational complexity of recent ML models such as deep neural networks, inference deployments have been limited by performance and cost constraints.
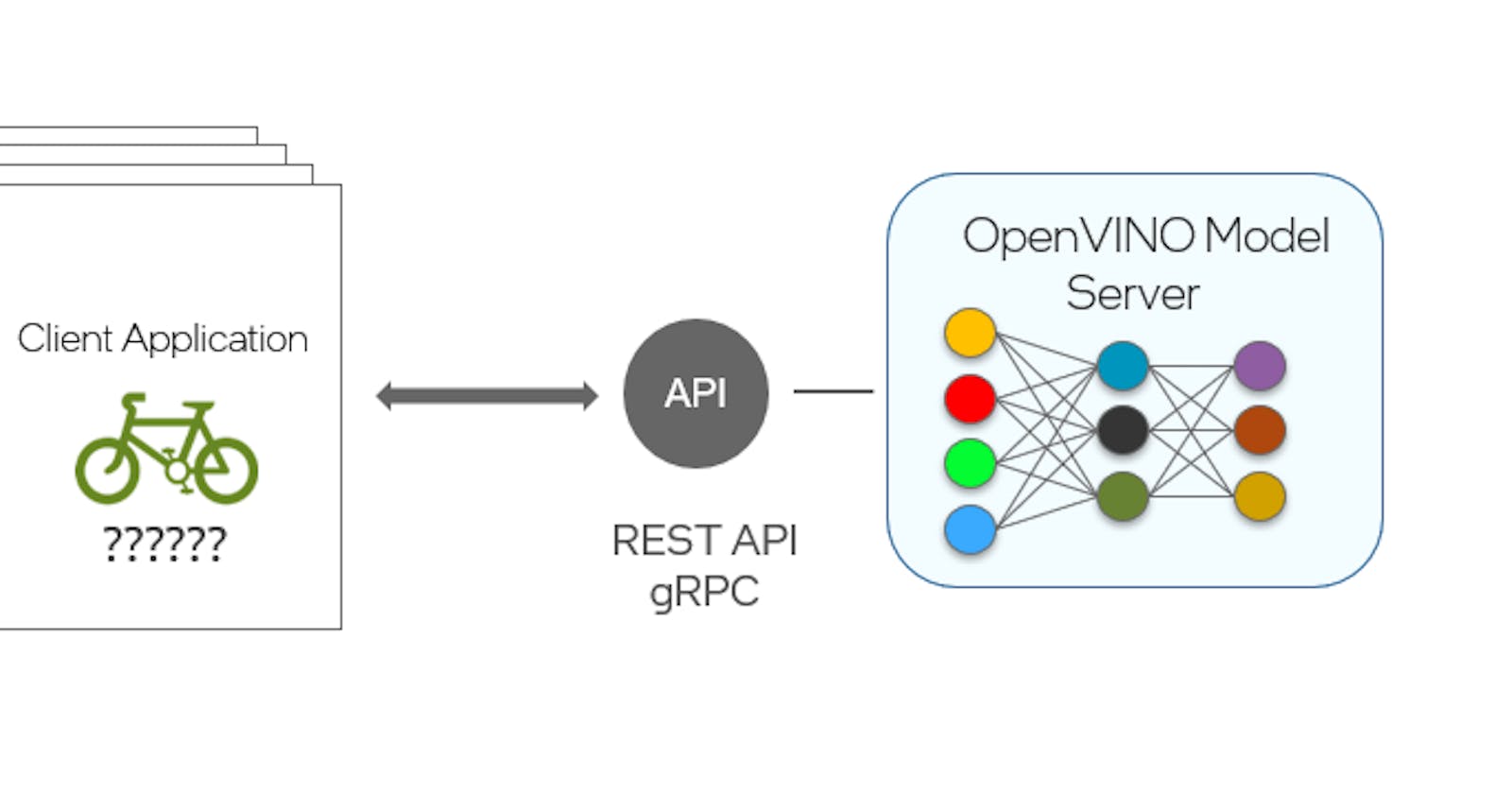
Fundamentally a model server is a web server that hosts the deep learning model and allows it to be accessed over standard network protocols. Functionally it is similar to a web server as well. You send a request to get back a response. Similarly, just like a web server, the model can be accessed across devices as long as they are connected via a common network.
The primary advantage that a model server provides is its ability to “serve” multiple client requests simultaneously. This means that if multiple applications are using the same model to run inference, then a model server is the way to go.
This extends to a second advantage, that is, since the same server is serving multiple client requests simultaneously, the model does not consume excessive CPU/GPU memory. The memory footprint roughly remains the same as that of a single model. Further, the model server can be hosted on a remote server (e.g., AWS, Azure, or GCP), or locally in the same physical system as your client(s). The inference latency would vary depending on the closeness of the server to the client and the network bandwidth. Though a large number of simultaneous requests would slow down the inference speed significantly, in which case, multiple instances of the model server can be hosted, and the hosting hardware can be scaled up as a solution.
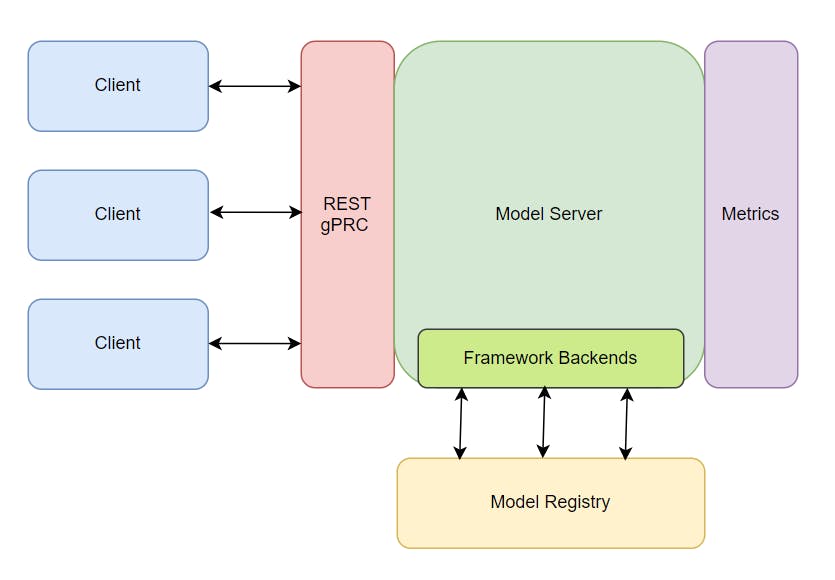
To put it simply, model serving is taking a trained AI model and making it available to software components over a network API. To make life easier for our developers, OpenVINO™ toolkit offers a native method for exposing models over a gRPC or REST API. It’s called the OpenVINO™ model server (OVMS).
The OpenVINO™ model server enables quickly deploying models optimized by OpenVINO™ toolkit – either in OpenVINO™ toolkit Intermediate Representation (.bin & .xml) or ONNX (.onnx) formats – into production.
So, a model server lets you build a similar platform to deliver inference as a service.
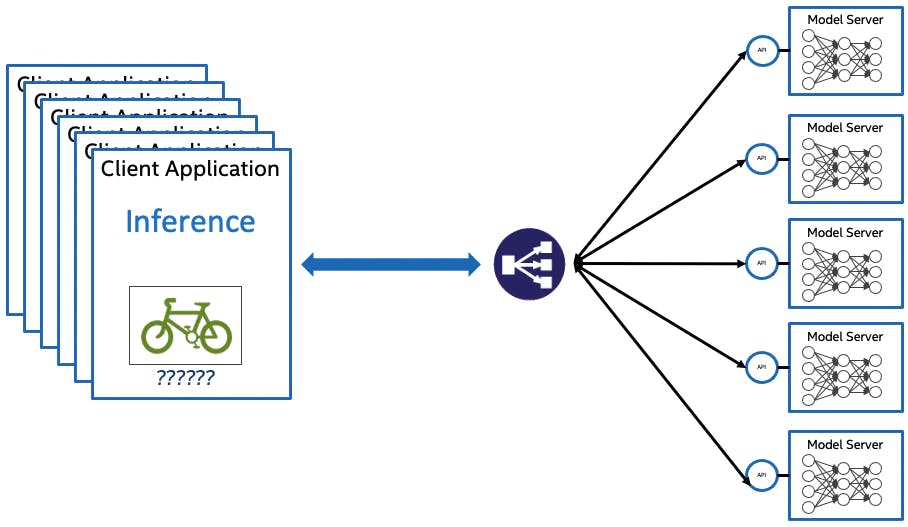
Inferencing with OpenVINO™ model server can be scaled to thousands of nodes using multiple pod replicas in Kubernetes or OpenShift clusters. Kubernetes and Red Hat OpenShift can run on most public clouds, or on-premises in a private cloud or edge deployment.
To run the image, use the following command:
docker pull openvino/model_server
OpenVINO Model Server demos have been created to showcase the usage of the model server as well as demonstrate it’s capabilities.
Happy Inferencing as a Service 🤩🤩🤩