Deep Learning Deployment with Intel OpenVINO
AI Inference Optimized for Amazing


Intel's goal has been to provide an unparalleled AI development and deployment ecosystem that makes it as seamless as possible for every developer, data scientist, researcher, and data engineer to accelerate their AI journey from the edge to the cloud.
> When the WHY is clear, the HOW is easy!
So to enable AI for all, we need a tool that enables domain experts to develop and infer using Deep Learning models on right-sized hardware from the edge to the cloud.
Intel OpenVINO solves one of the most difficult challenges when it comes to deploy your Deep Learning models.
- It makes it easier for developers to add artificial intelligence to their applications
- It ensures those applications can execute at the highest levels of performance across any Intel hardware architecture
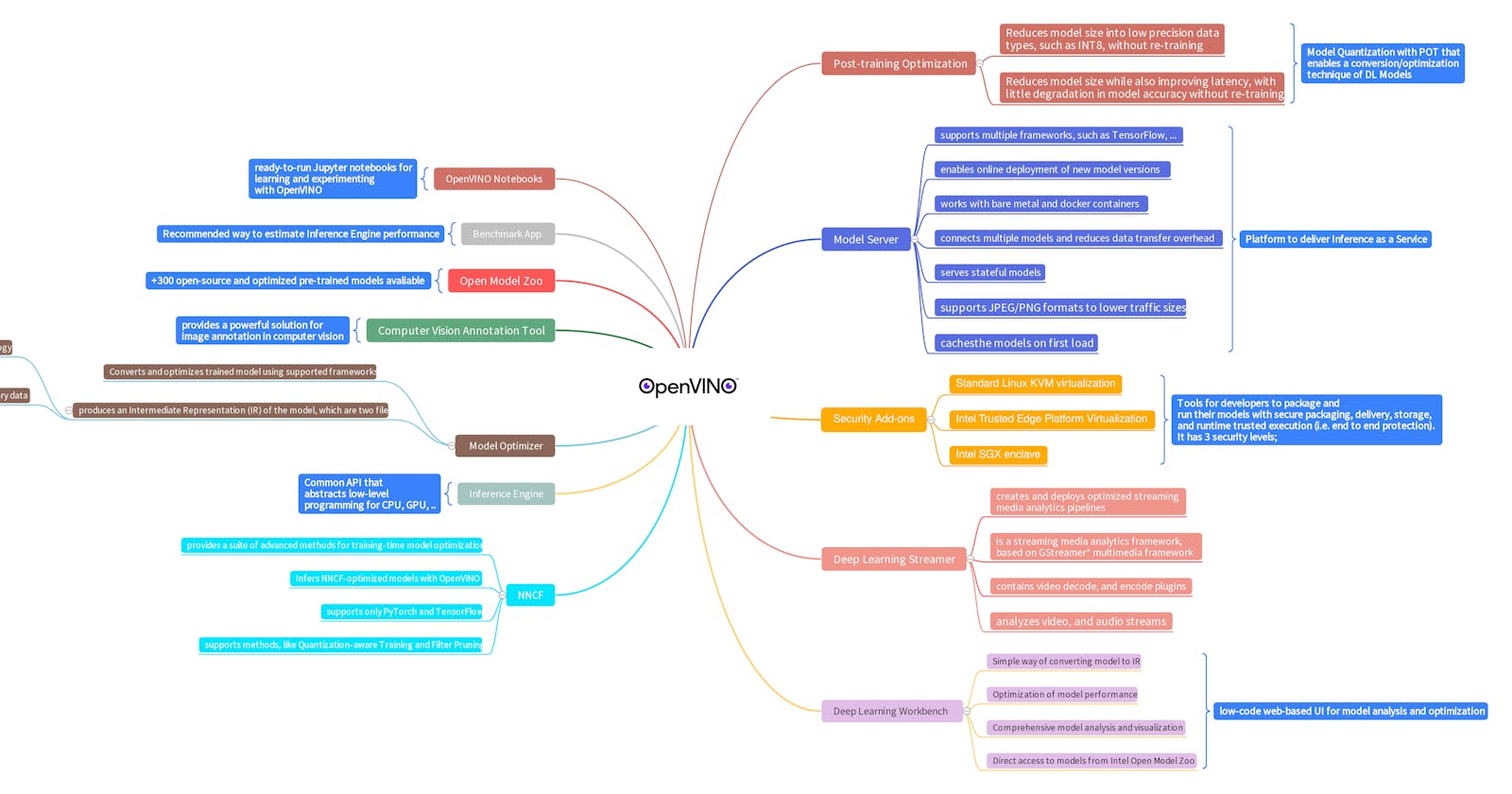
It’s one of the best tools for neural network model optimization, when the target device is: Intel hardware like the Intel CPU, integrated GPU, FPGA, or discrete GPU.
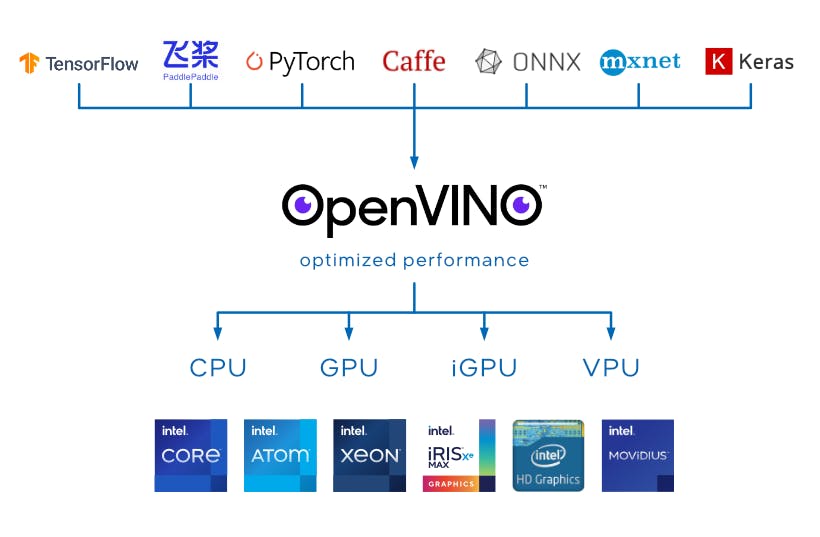
To put it simply, Intel OpenVINO takes a trained model from a framwork of choice like TensorFlow, PyTorch, PaddlePaddle, ... and optimize the model so it can run efficiently on Intel Hardware Architecture.
Why choose the OpenVINO Toolkit?
For now, let’s list out a few important points that make the OpenVINO Toolkit stand out.
- It supports neural network architectures for computer vision, speech and natural language processing.
- OpenVINO Toolkit supports a wide range of Intel hardware, including CPUs, Integrated GPUs and VPUs.
- It also has an official Model Zoo, which provides many state-of-the-art, pre-trained models (+300 pre-trained models). All these models are already optimized for the OpenVINO toolkit, and provide fast inference straight out of the box.
- Contains many optimizations tools that speed up the scalability of neural-network deployment.
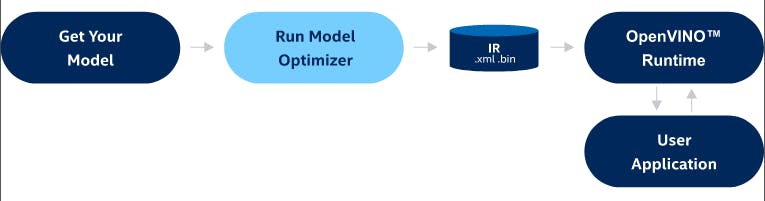
A bird's-eye view of OpenVINO
- We start by training a Deep-Learning model with the framework of our choice.
- Next, run the model optimizer to obtain the optimized IR (Intermediate Representation), in the form of a .xml and .bin file.
- After that, employ OpenVINO’s Inference Engine to carry out inference.
- Finally, we deploy our neural network model, after packaging it into a user application.
The OpenVINO Toolkit represents neural network models with the help of two files:
- An XML (.xml) file—this file contains the neural network topology, more commonly known as the architecture.
- A binary (.bin) file—it contains the weights of the neural network model.
Last month Intel has released the biggest upgrade for the OpenVINO™ toolkit 2022.1 in 3.5 years. If you want to download, convert, optimize and tune pre-trained deep learning models, install OpenVINO™ Development Tools, which provides the following tools:
- Model Optimizer imports, converts, and optimizes models that were trained in popular frameworks to a format usable by OpenVINO components. Supported frameworks include Caffe, TensorFlow, MXNet, PaddlePaddle, and ONNX*
mo
- Benchmark Application allows you to estimate deep learning inference performance on supported devices for synchronous and asynchronous modes.
benchmark_app
- Post-Training Optimization Tool allows you to optimize trained models with advanced capabilities, such as quantization and low-precision optimizations, without the need to retrain or fine-tune models
pot
- Model Downloader is a tool for getting access to the collection of high-quality and extremely fast pre-trained deep learning public and Intel-trained models.
omz_downloader
- Model Converter is a tool for converting Open Model Zoo models that are stored in an original deep learning framework format into the OpenVINO Intermediate Representation (IR) using Model Optimizer.
omz_converter
- Model Quantizer is a tool for automatic quantization of full-precision models in the IR format into low-precision versions using the Post-Training Optimization Tool.
omz_quantizer
- Model Information Dumper is a helper utility for dumping information about the models to a stable, machine-readable format.
omz_info_dumper
Example of converting/optimizing models by Intel OpenVINO
omz_downloader -h
-h option means help
omz_downloader --print_all
--print_all option means list all available models
omz_downloader --name yolo-v4-tiny-tf
--name option means model name
omz_converter --name yolo-v4-tiny-tf -o output-conversion
-o option means directory to place converted files into
You can use Netron to give you an idea of the look and feel of Deep Learning models.
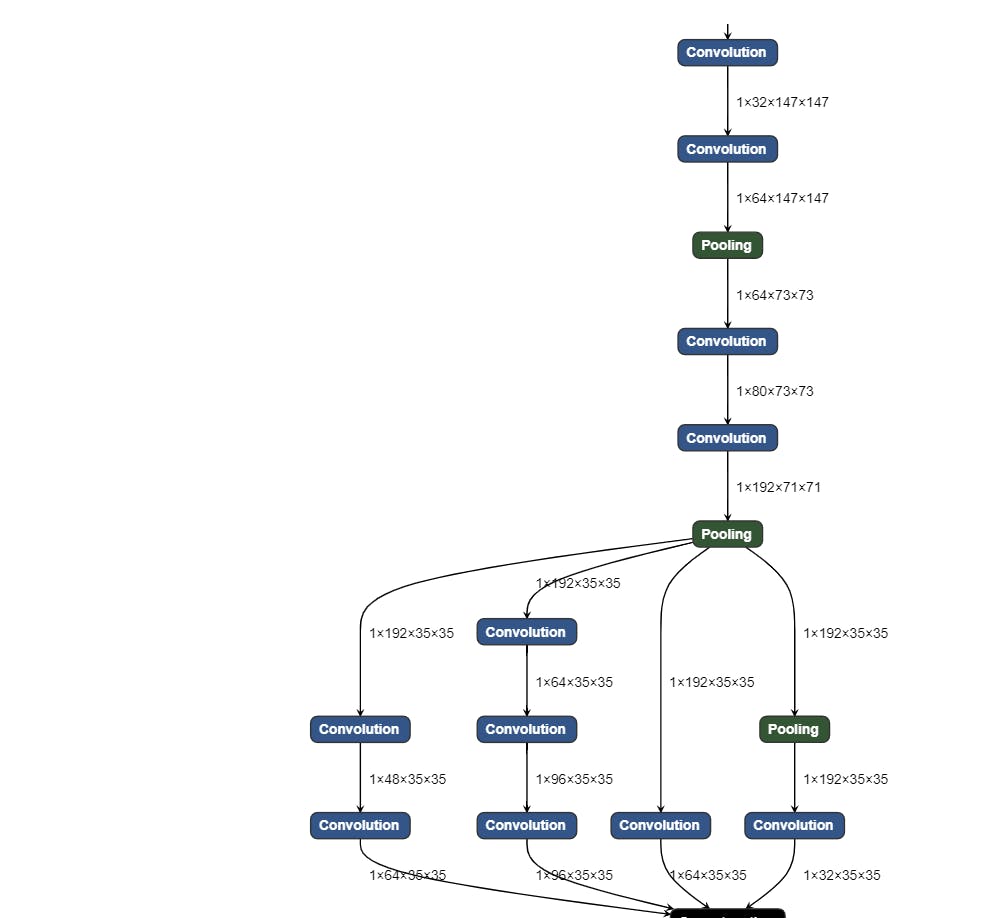
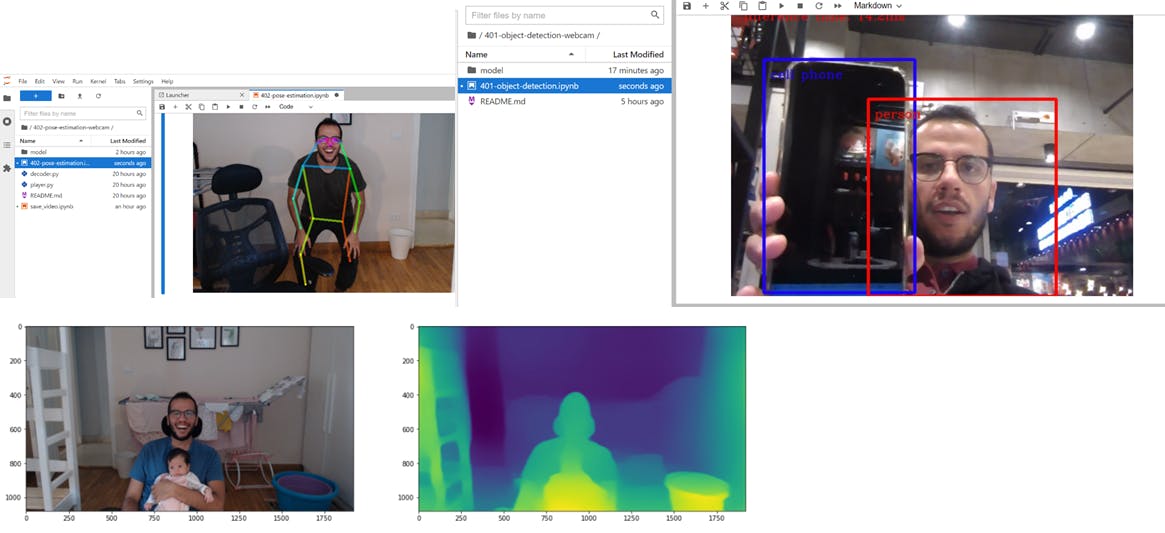
Also you can try OpenVINO Notebooks, which is a collection of ready-to-run Jupyter notebooks for learning and experimenting with the OpenVINO™ Toolkit.
Let's make it together and create something wonderful 🤩